wallhog
‘Across the Great Wall, we can reach every corner of the world. ‘
It is said to be a sentence in an email sent from China in 1987 which sounds interesting in 2020. For a relatively okay connection to the world - here connection refers to web search, I’ve been collecting and using some sites which are not blocked by the wall meanwhile provide not that man-made results. But for some reasons like DNS as mentioned in my previous post, the distance to the server, etc., connection is always a problem. Take 5+ minutes to wait for a response which might be timeout? In this situation, I used to switch to another one on my list to see if that would work.
You might notice, for a single search, I need 5+ minutes * times I tried, which is still time consuming. Why not trigger them at the same time? I thought. Here comes wallhog.
wallhog is simple. When I want to search something, what I need to do is:
- open my terminal
- type the few wallhog commands with what I want to search and which search engine(s) I want to use (optional)
- press Enter
It would pick up the search engine(s) from my site collection, open my default browser then search with the keyword via the engine(s) in different tabs, ‘concurrently’.
Example 1: Search ‘golang’
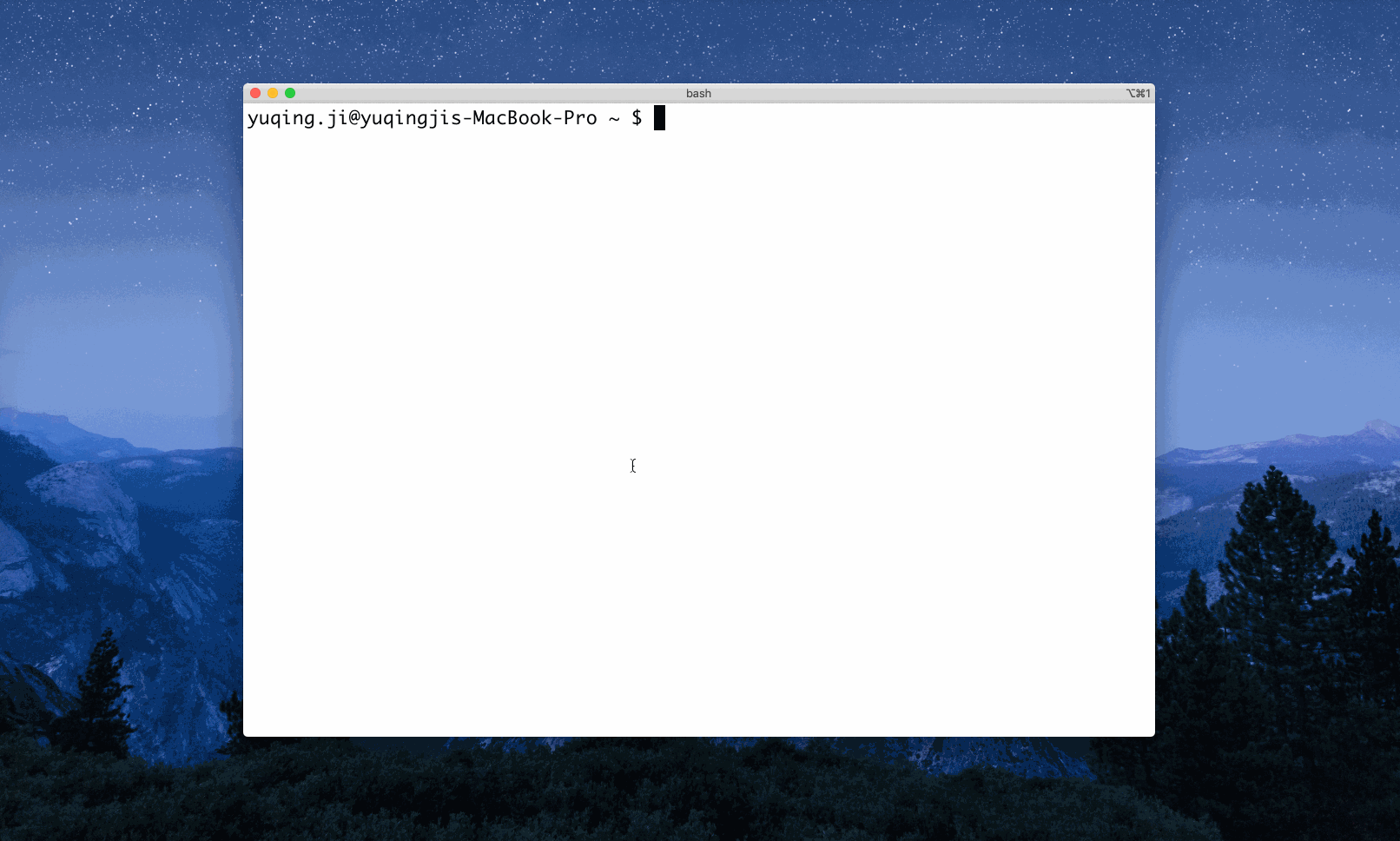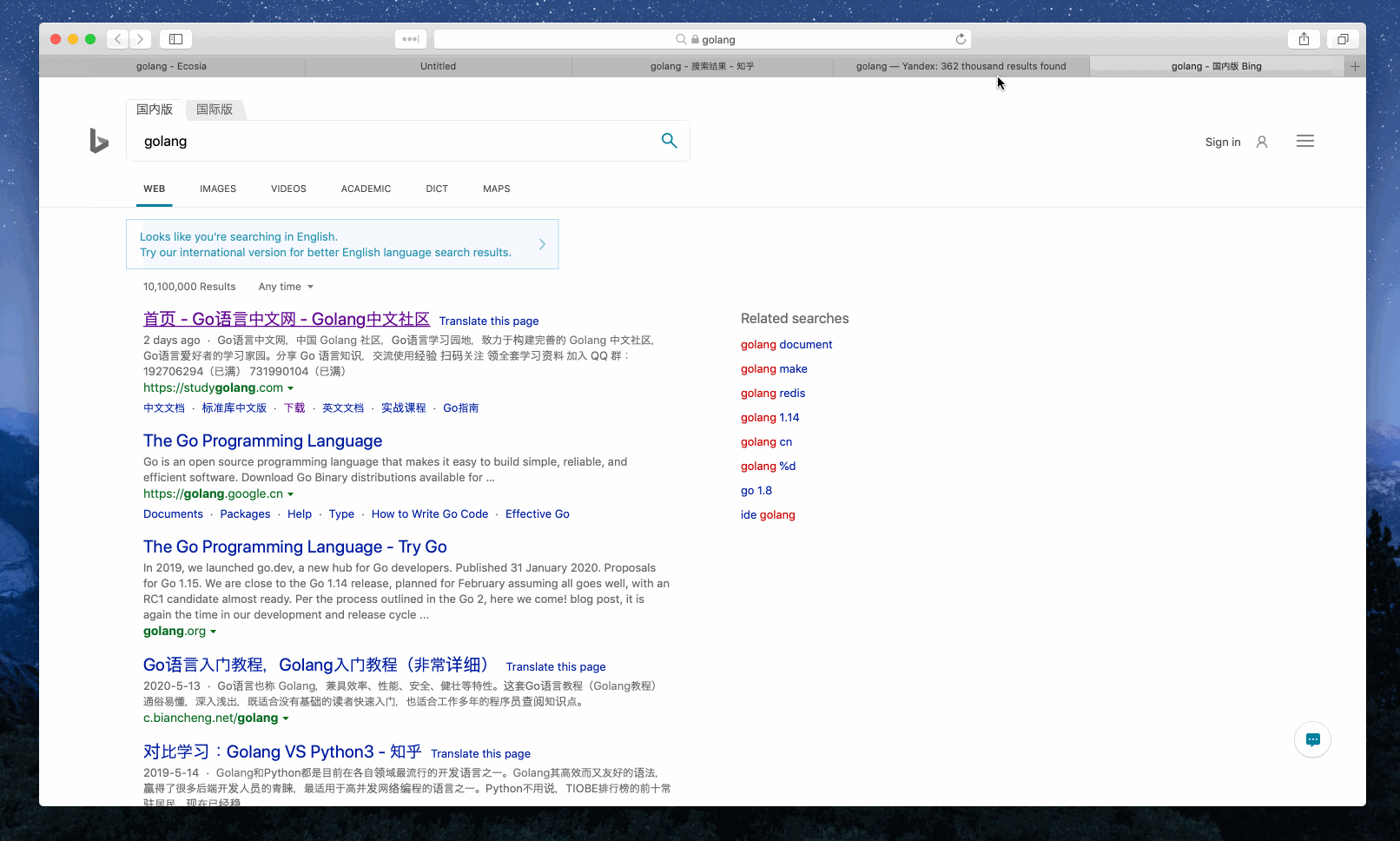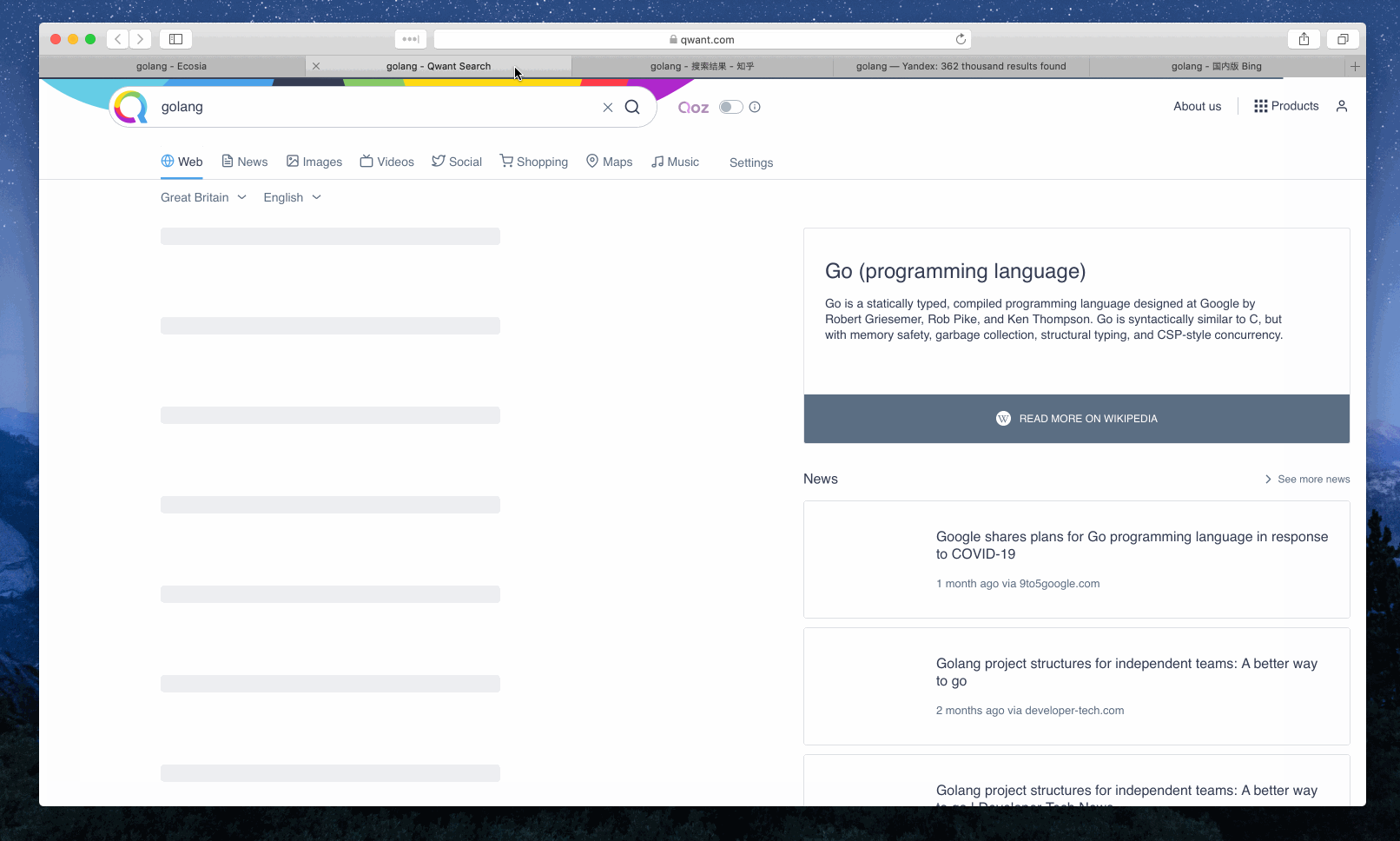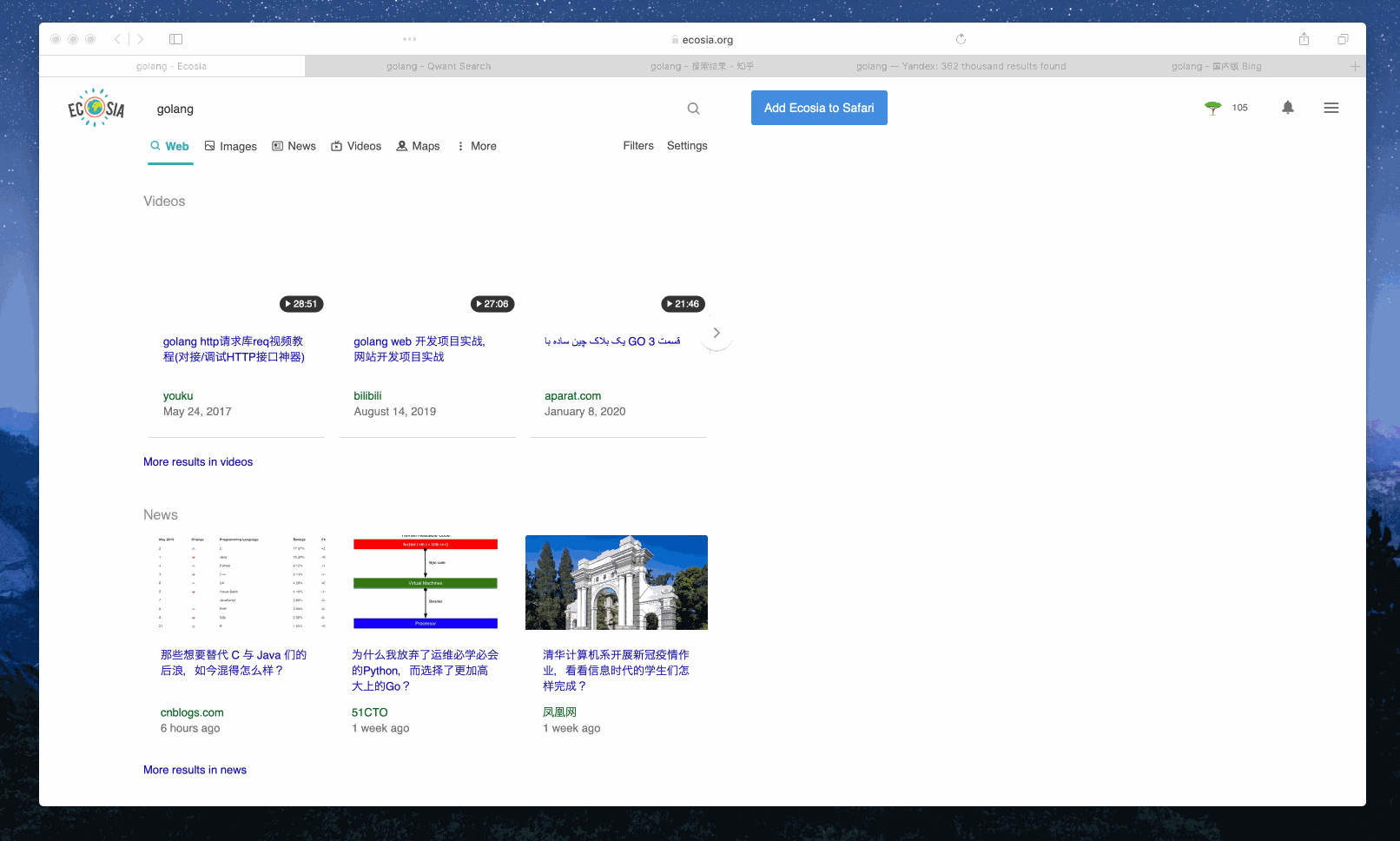
Example 2: Search ‘the little schemer’ via the search engines tagged with ‘book’
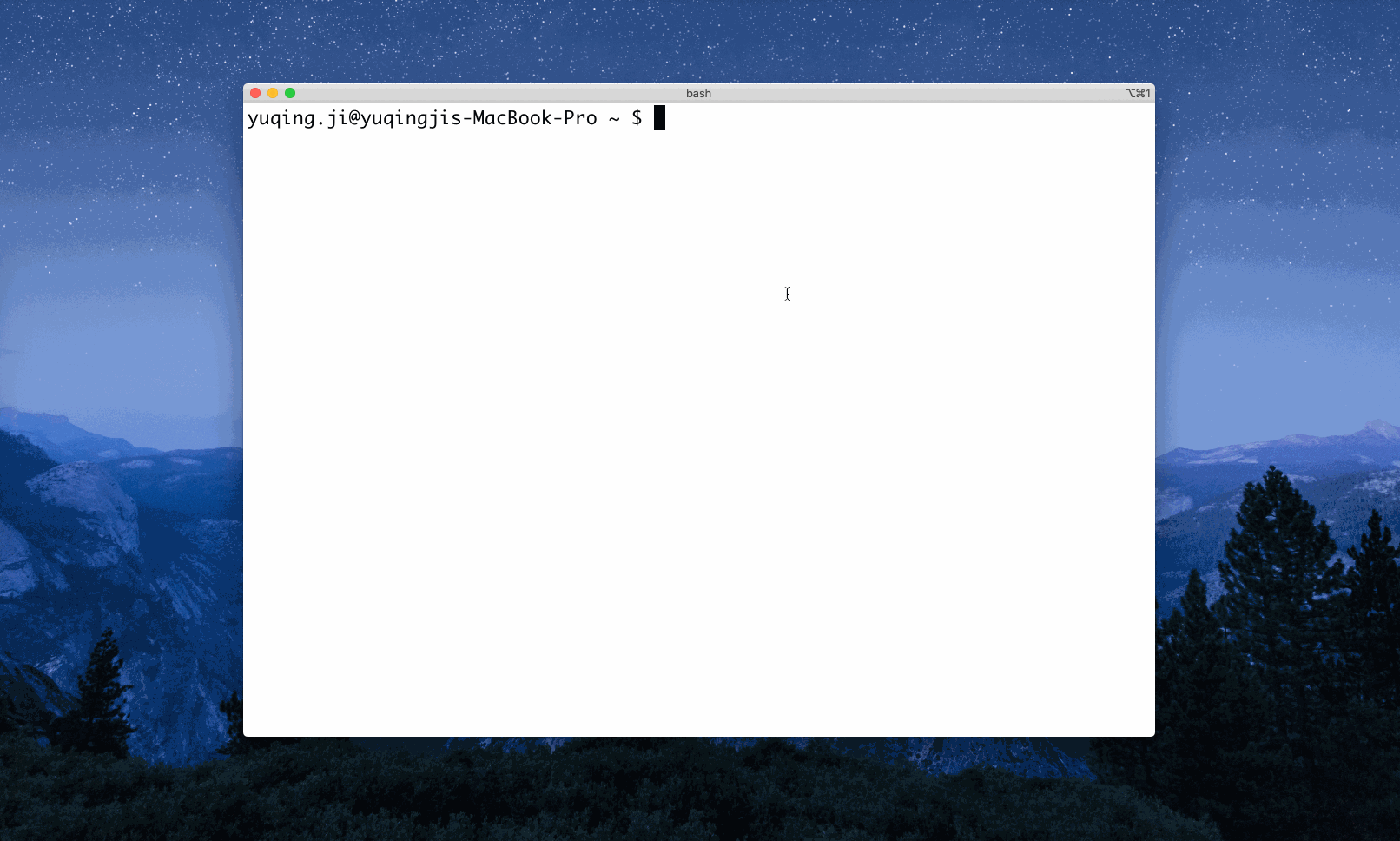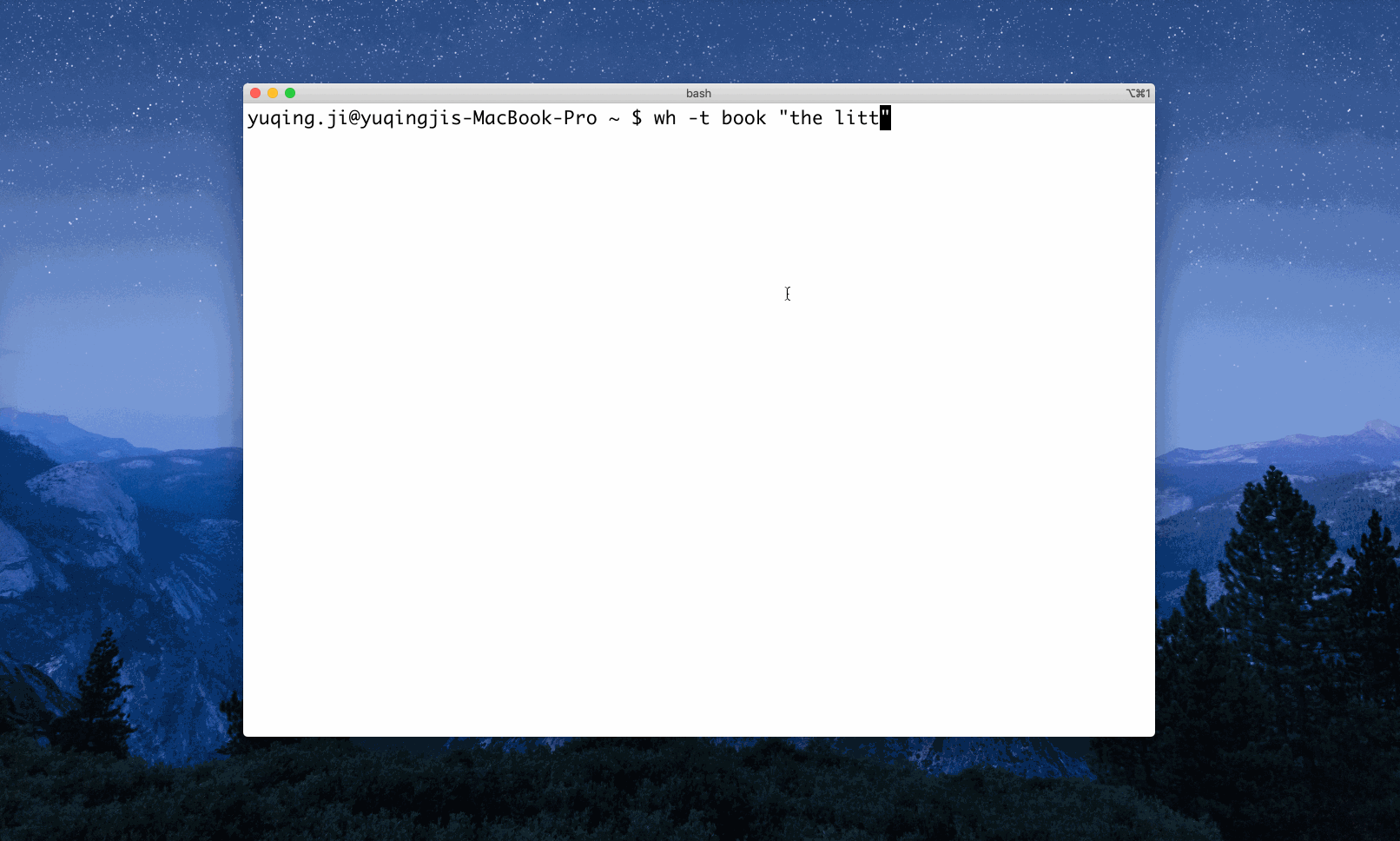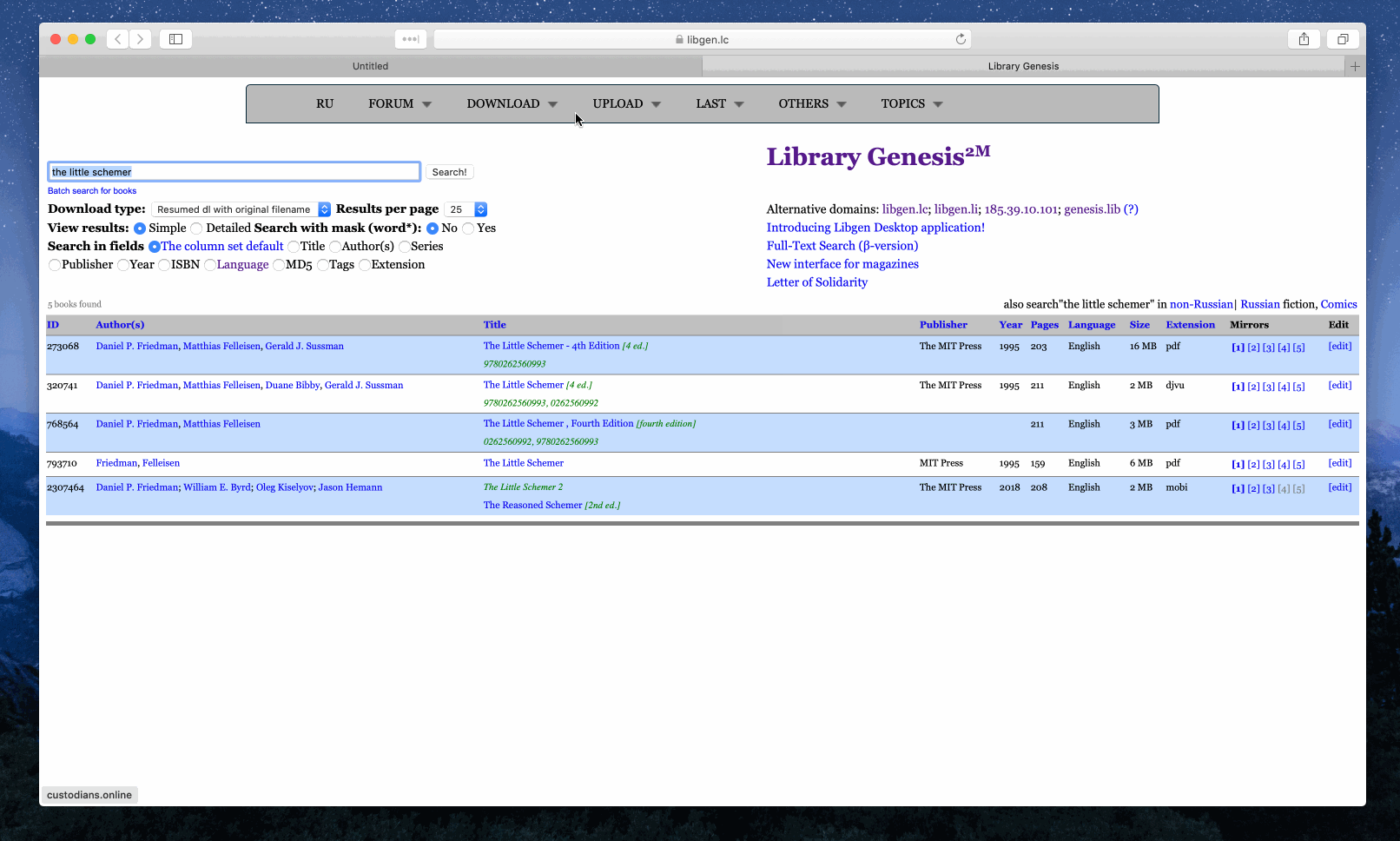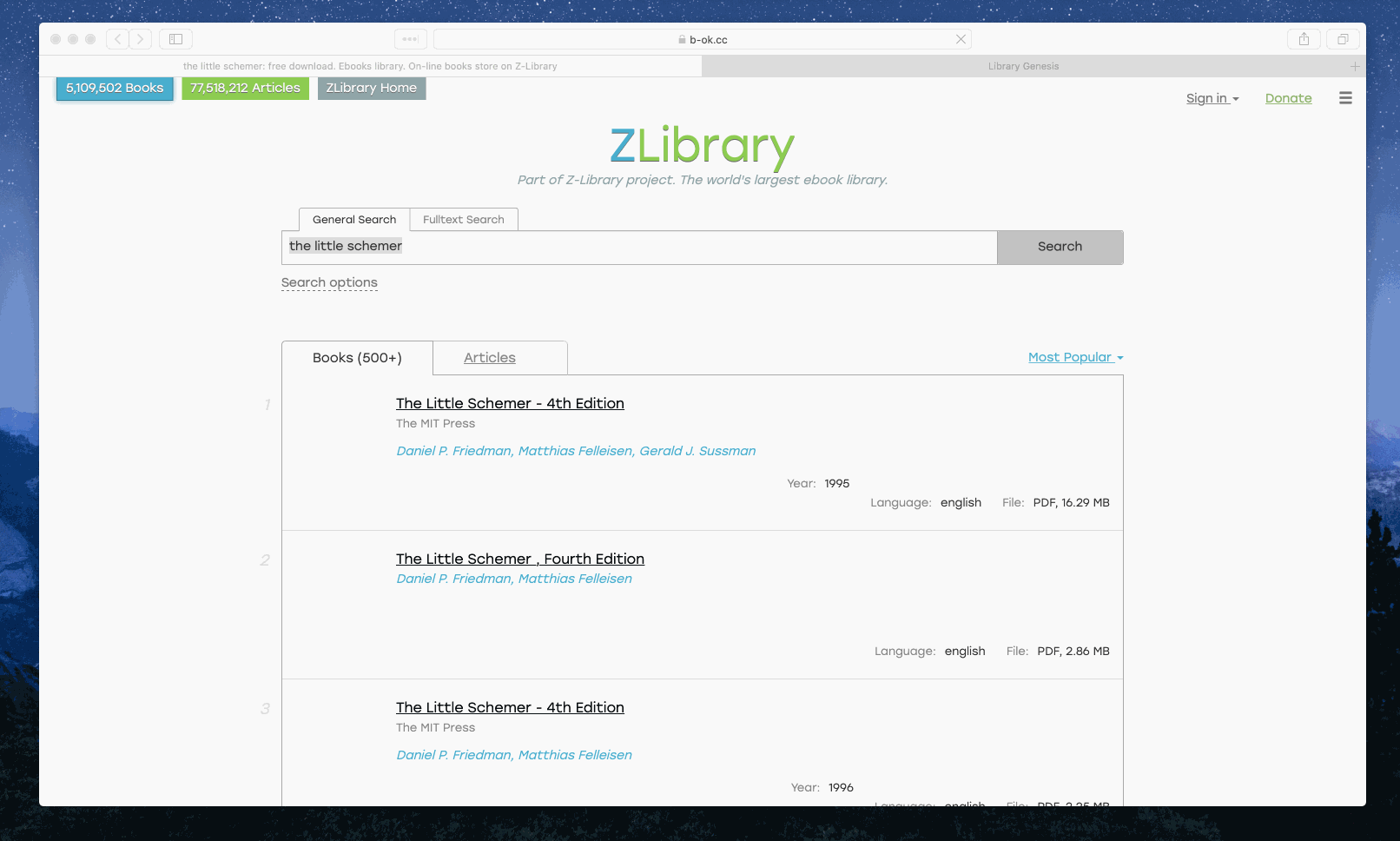
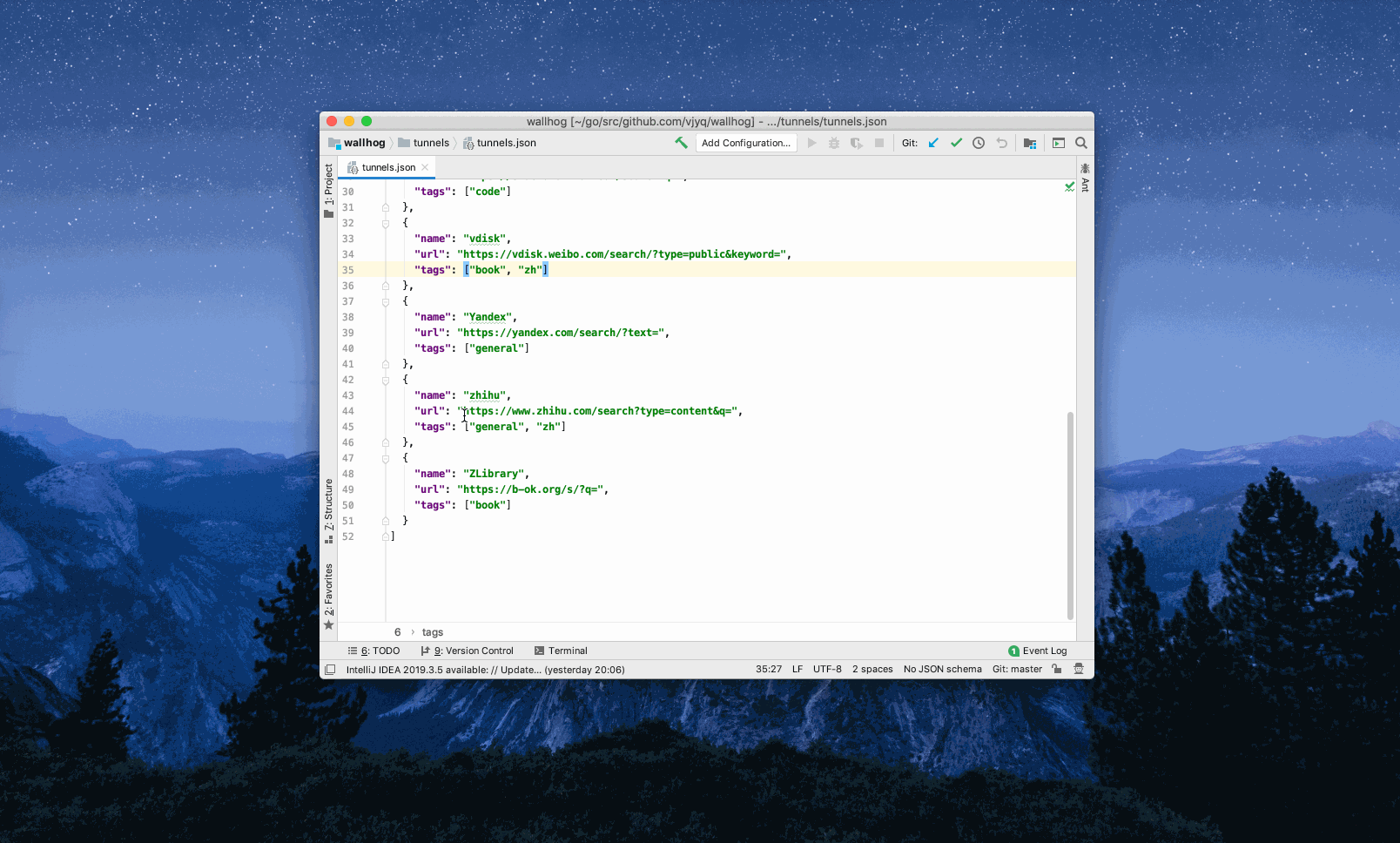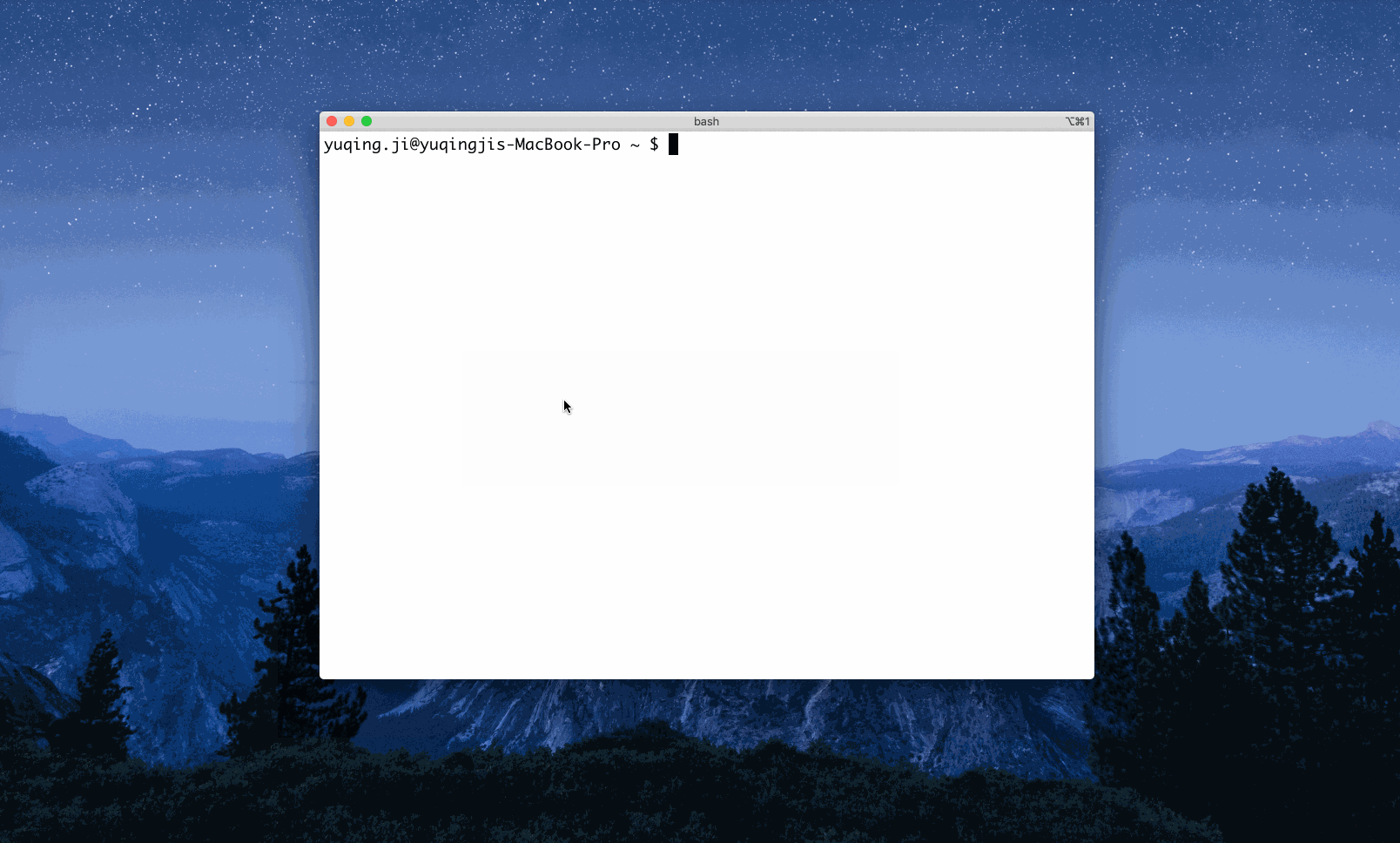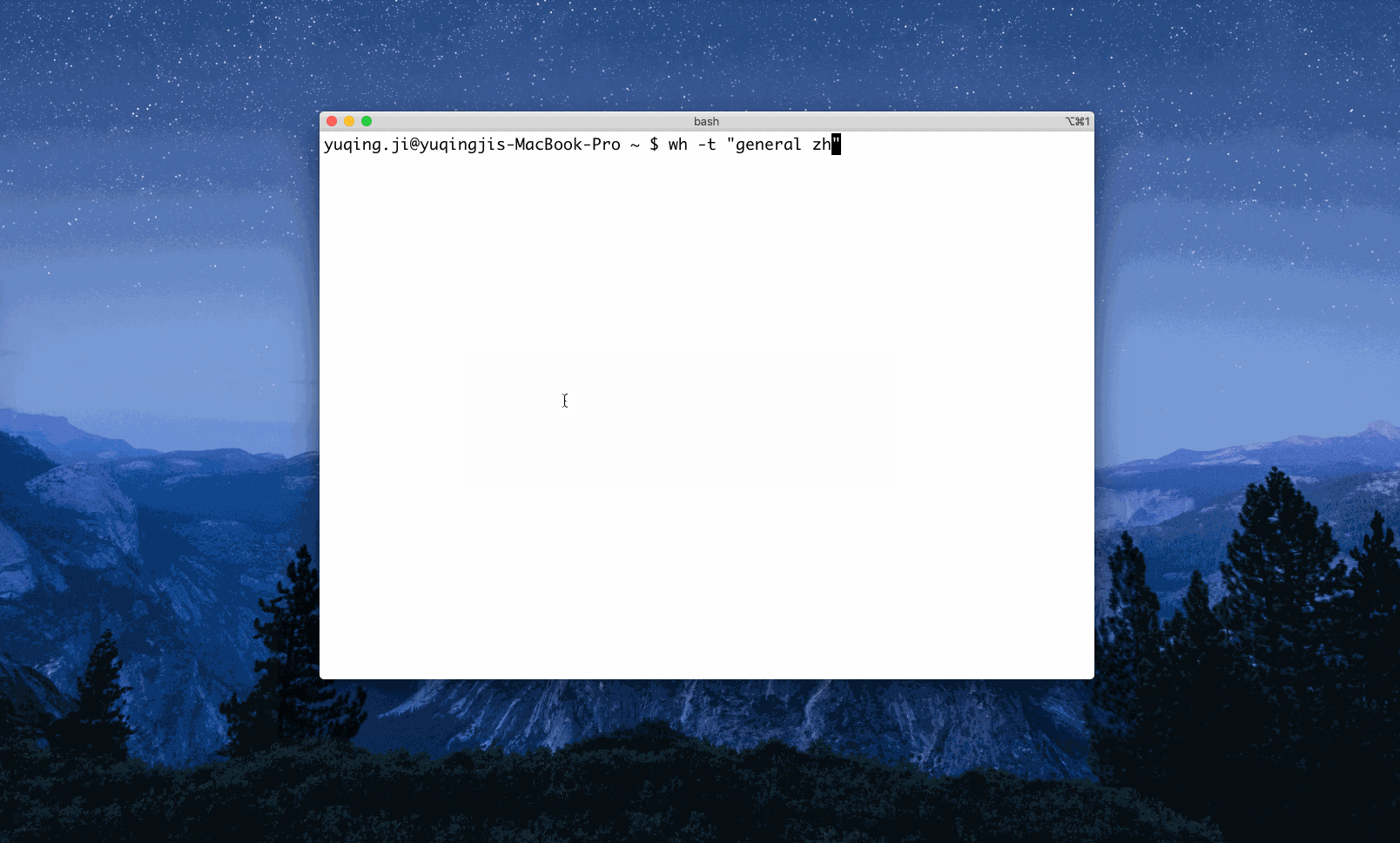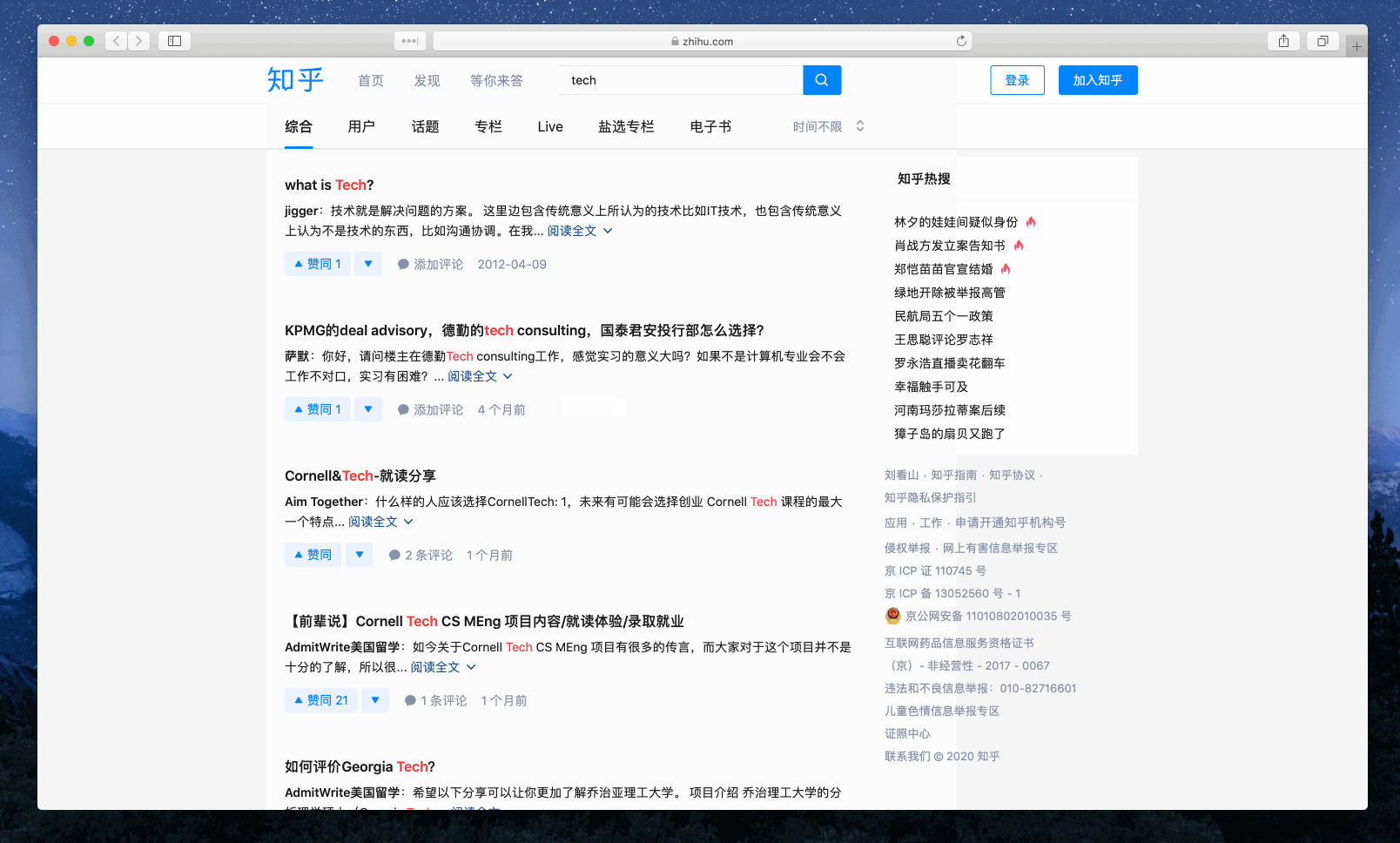
Example 3: Search ‘tech’ via the engines tagged with both ‘general’ and ‘zh’ - ‘zh’ refers to Chinese. As you can see, only the ones with all the desired tags would be triggered.
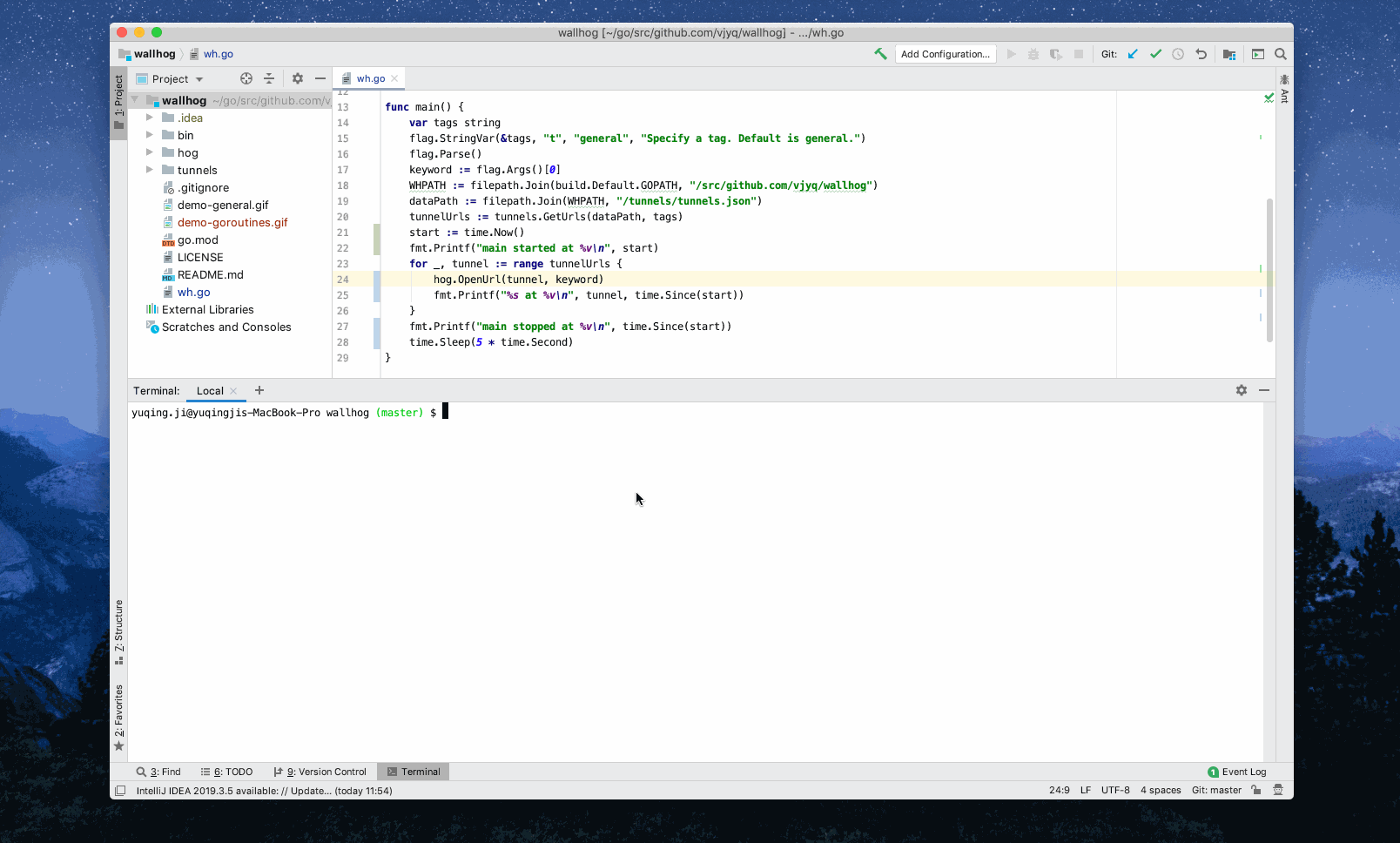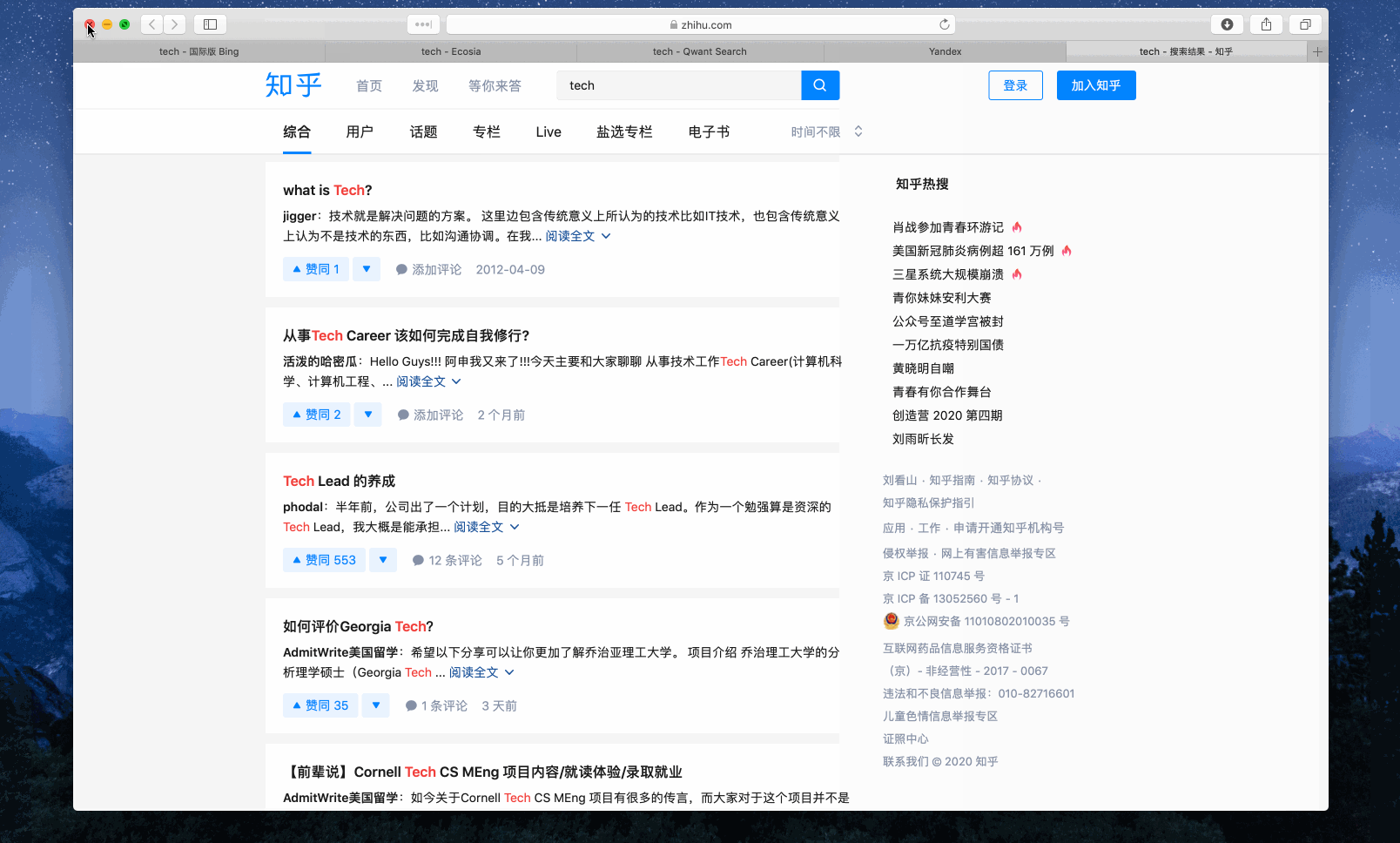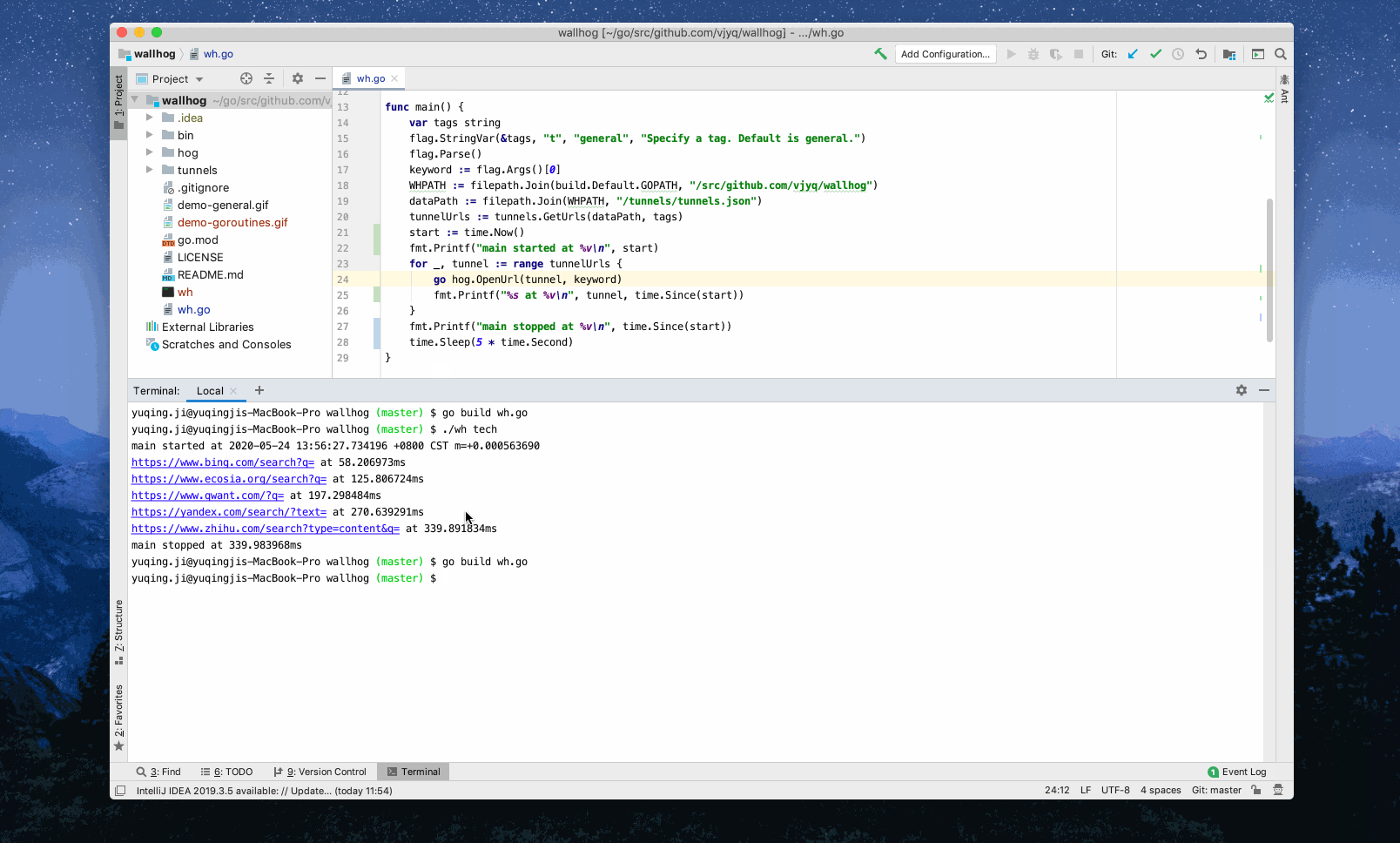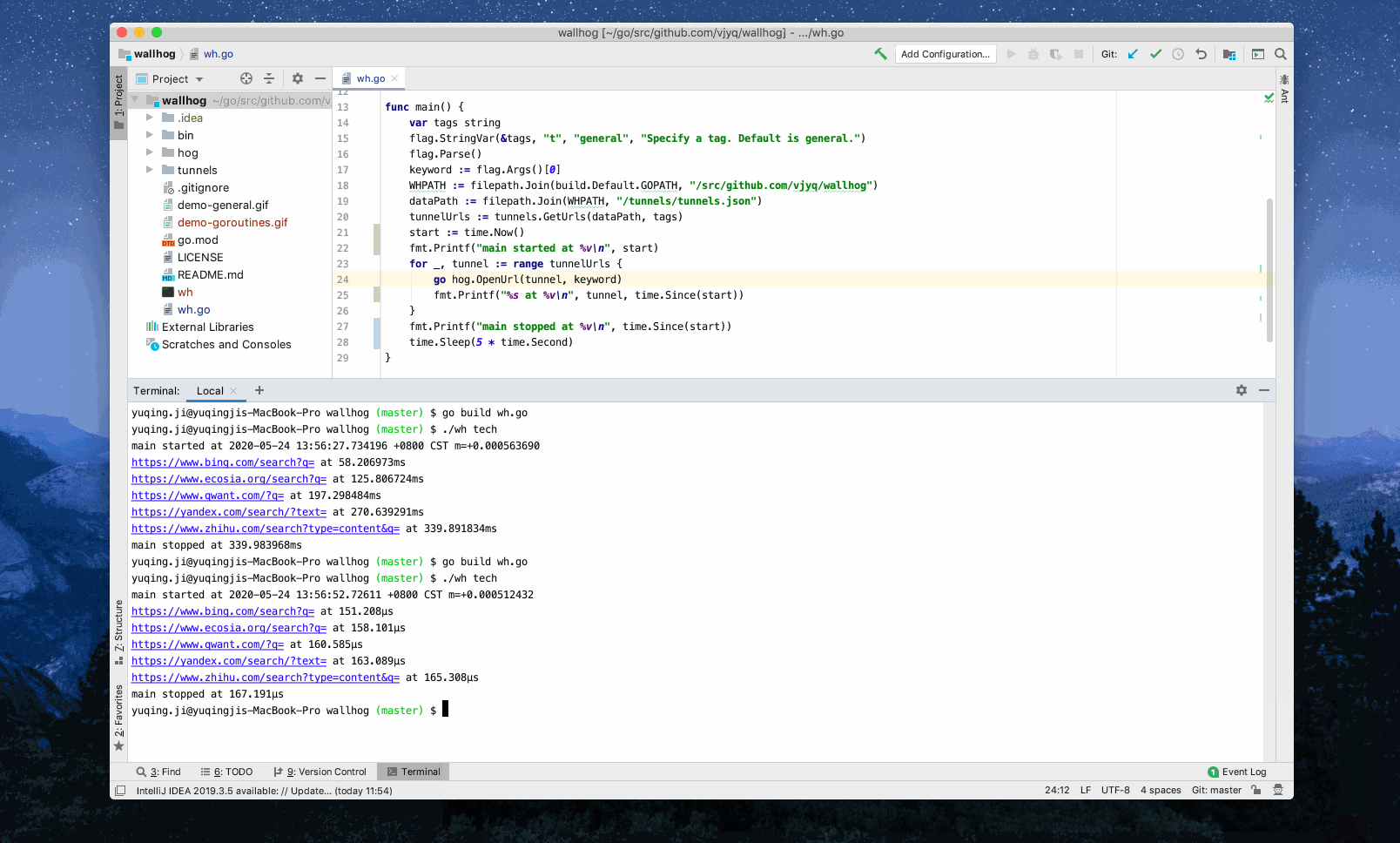
I made the concurrent action with goroutines. Here’s the reason: